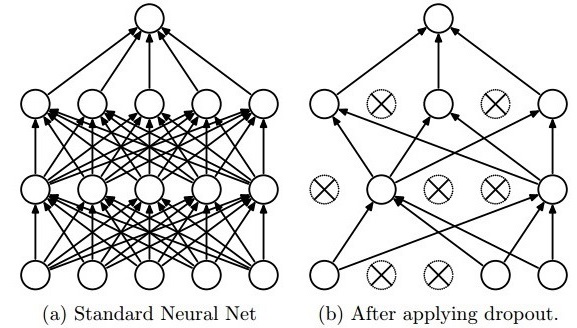
Accepts as input:
- feature vector of size
- probability
Weight decay
Soft
constraint on the parameters of the network.
This is done by decreasing every parameter in each iteration of SGD by its value times a small constant, corresponding to the strength of the regularization.
Max norm constraints
Hard
constraint on the parameters of the network.
This is done by imposing an upper bound on the
norm of every filter and using projected gradient descent to enforce the constraint.
source
Data augmentation
Creating additional training samples by perturbing existing ones. In image classification this includes randomly flipping the input, cropping subsets from it, etc.