Gradient descent
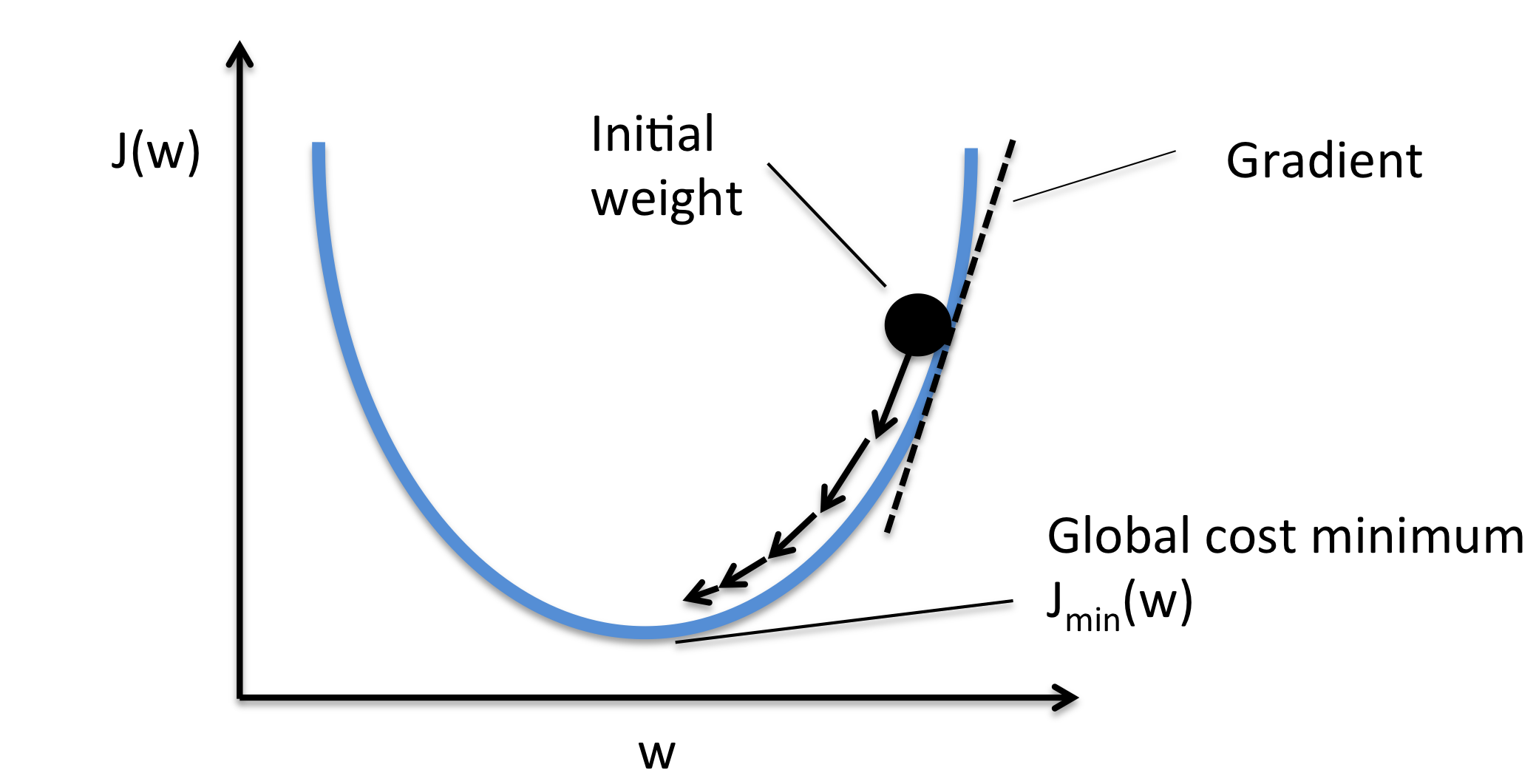
To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient of the function at the current point.
source
image source
Stochastic gradient descent (SGD)
A stochastic approximation of the gradient descent for minimizing an objective function that is a sum of functions.
The true gradient is approximated by the gradient of a randomly chosen single function.
source
Initialization of a network
Usually, the biases of a neural network are set to zero, while the weights are initialized with independent and identically distributed zero-mean Gaussian noise.
The variance of the noise is chosen in such a way that the magnitudes of input signals does not change drastically.
source
Learning rate
The scalar by which the negative of the gradient is multiplied in gradient descent.
Backpropagation
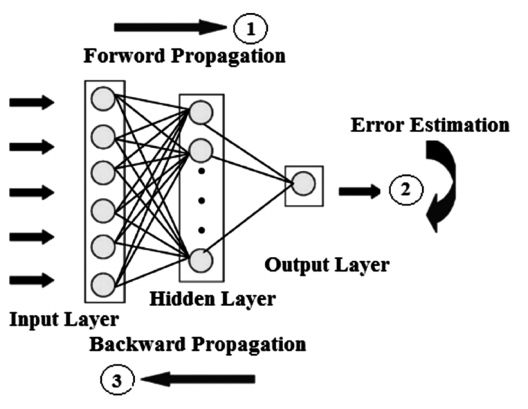
An algorithm, relying on an iterative application of the chain rule, for computing efficiently the derivative of a neural network with respect to all of its parameters and feature vectors.
source
image source
Goal function
The function being minimized in an optimization process, such as SGD.
Data preprocessing
The input to a neural network is often mean subtracted, contrast normalized and whitened.

One-hot vector
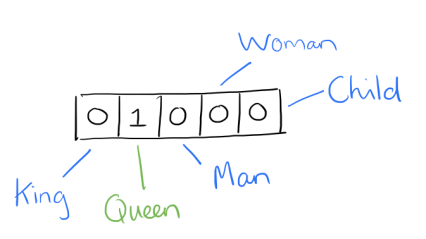
A vector containing one in a single entry and zero elsewhere.
image source
Cross entropy
Commonly used to quantify the difference between two probability distributions. In the case of neural networks, one of the distributions is the output of the softmax, while the other is a one-hot vector corresponding to the correct class.
Added noise
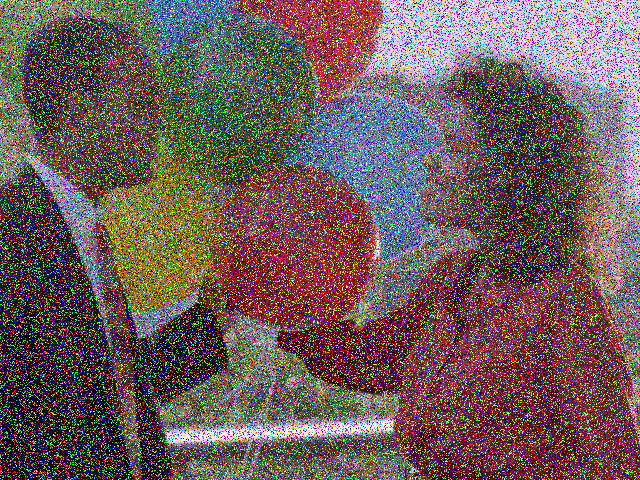
A perturbation added to the input of the network or one of the feature vectors it computes.
image source